Lessons on agent creation
Key lessons learned from building an intelligent agent.
In 2025, everyone went crazy about intelligent agents and automated customer support. In that context, a friend asked me if I knew how to build one. While he had seen countless platforms offering “ready-to-use” and “easy-to-configure” agents, what he really wanted was to validate a business idea before fully committing to a specific solution. I replied with my classic phrase: “I don’t know, but I can learn.” And so I set out to build an intelligent agent using n8n and WhatsApp, with the goal of quickly evaluating how this technology could be applied to customer service scenarios.
The first thing I discovered is that, from a technical perspective, it is very easy to build an intelligent agent with these tools. In fact, strictly speaking, you only need four nodes in n8n to get a basic agent up and running.
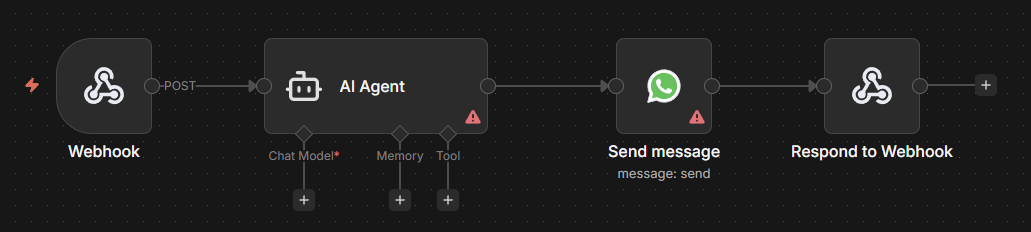 Yes, if you configure these nodes correctly, you can have a basic agent up and running in minutes.
Yes, if you configure these nodes correctly, you can have a basic agent up and running in minutes.
The real lessons came afterward, when I started analyzing how the agent behaved with real users. I learned several things that are not obvious at first glance, but that I now consider essential for the success of any project of this kind. These aspects are independent of the technology used, as I’ve seen them appear across different AI initiatives.
Today, if I have to start a new intelligent agent project, the first things I consider are the following three points.
Managing AI expectations
With all the hype around AI, many people who are not familiar with the technology tend to overestimate its capabilities. Implementations like ChatGPT or Gemini have created the impression that AI can understand and accurately answer any question (or with minimal error). For many users, the experience with these platforms has been so smooth and satisfying that they assume any intelligent agent should behave the same way. And to be fair, if you ask a simple question (“What fruits can my dog eat?”) you will most likely get an answer that feels correct and complete.
But as you start pushing the system further, small cracks begin to appear. The more complex or specific the request, the more the accuracy tends to degrade. If you add elements like file attachments or integrations with other platforms, the probability of errors or hallucinations increases significantly.
That’s why it is essential to actively manage expectations when someone wants to build an intelligent agent. It’s not just about explaining what AI can do, but also about making its limitations explicit, and about being honest regarding the situations in which results are more likely to fall short. There needs to be a demystification effort so customers understand that, no matter how magical AI may seem, it is not infallible, and its performance can vary greatly even in seemingly similar scenarios. This is where clients often say they want their agent to “be like ChatGPT but for my business,” without realizing that context, complexity, and the specific constraints of their use case can lead to very different outcomes.
After a quick introduction to what AI can and cannot do, clients usually follow with a simple question: “Can what I want be done or not?” And my answer is always the same: everything can be done… with clear objectives, enough time, and resources.
From there, the real work begins: defining what the client actually wants. Because of their familiarity with their own business, clients often omit details that seem obvious to them but are critical for implementation. This is, of course, a necessary step in any software project. A proper requirements discovery process is essential to define scope and avoid misunderstandings that later turn into frustration. However, working with AI introduces a different kind of challenge.
If you’re asked to build an API that returns a list of orders, there may be variations in how that list is structured (pagination, sorting, filters) but the expected outcome is still relatively clear: a list of orders with certain fields.
With AI, expected outcomes are much more ambiguous. Something as simple as defining the tone the agent should use when interacting with users can be surprisingly difficult to implement consistently. It may seem minor or trivial, but aspects like this can make the difference between a solution that feels right and one that doesn’t.
That’s why I try to be transparent about both the capabilities and limitations of AI, and to frame the conversation around expectations. Once expectations are clear, it becomes possible to define concrete objectives. And from there, measurable success metrics.
Defining clear ways to measure success
What my friend needed sounded simple, at least in theory: an autonomous agent that could interact with potential users for a real estate project selling land plots. The customer explained it to us like this:
I want people to be well taken care of on WhatsApp 24/7.
At first, I imagined a fairy simple flow:
flowchart TB
A[User sends message via WhatsApp] --> B[Agent receives message]
C[FAQ database] -- Context --> D
B --> D[Agent processes message]
D --> E[Agent responds with relevant information]
After several iterations, the final implementation looked somewhat different:
flowchart TB
A[User sends message via WhatsApp] --> B[Agent receives message]
C[FAQ database] -- Context --> D
B --> D[Agent processes message]
B --> M[LLM classifies lead]
M --> G
D --> E[Agent responds]
L[Media: images/videos/brochures] --> F
E --> F[Agent sends media if needed]
K[Calendly] --> H
F --> H[Agent informs about scheduled visits]
H --> I[Agent sends follow-up]
J[Odoo] <-- Leads --> G
J -- Stages and tags --> M
I --> G[Agent creates/updates lead]
Why such a big difference? Because of the phrase “well taken care of.” What does that actually mean?
Does it mean answering basic questions? Which ones? What if the agent admits it doesn’t know something (which is a completely valid situation) but promises to escalate the issue to a human? Is that still considered “good service”?
A statement like “I want the agent to answer basic questions about the project” is not enough, because the understanding of what “basic” can vary widely depending on interpretation. In the worst cases, these definitions can even contradict each other. For example:
- The client doesn’t want the agent to talk about prices
- But wants it to answer questions about financing
- And also wants the agent to answer questions about payment methods
- And also about discounts and promotions
- But without mentioning prices…
Now imagine the client invests in a marketing campaign that brings in interested users. One of them asks about pricing and receives a response like: “Sorry, I can’t answer that.” Is that a good outcome?
Perhaps the client expected the agent to redirect the conversation, or to respond politely but indirectly, while also asking a follow-up question to maintain engagement.
And what happens if a user gets all their questions answered successfully, but then reaches the pricing topic and gets stuck in a loop without a clear answer? Is that a qualified lead? Or a lost one? If 60% of contacts don’t convert into qualified leads, is that a failure? With clear expectations, that same 60% could be seen as a great result: “Thanks to the agent, we filtered out noise that previously required hours of manual work.”
Because AI is non-deterministic, it becomes especially important to define both quantitative and qualitative metrics that allow you to evaluate whether the project is moving in the right direction. Working with vague or subjective indicators like “I want the agent to be good” or “useful” is simply not enough. Otherwise, you risk falling into the endless cycle of: “It’s good, but something is missing.” And that “something” can stretch a project far beyond its original scope, until you end up with an agent that solves 90% of the problem, but still can’t be clearly considered successful.
Understanding risks when AI fails or hallucinates
AI will make mistakes. Most often, it does so by hallucinating information or inventing answers that have no real basis.
The first is always a risk. The second can be mitigated, but doing so requires significant effort. And even then, it cannot be completely eliminated.
For example, a real case I experienced in the project I implemented: a potential buyer was very excited about the plots and was eager to go see them in person. So, he asked the agent if he could go visit them. The agent, very gladly, responded that of course he could. The user then asked about the location of the plots and the agent, based on a model that was trained with general information about the area, gave him the correct address. The user then asked for advice on how to get there and the agent, very kindly, gave detailed directions on which streets to take from different points in the city. The user, very grateful, followed the directions and headed to the plots. All this in real time and without human intervention. Finally, when the user arrived at the correct (and indeed real) address, he told the agent that he had arrived and was outside. The agent, without any malice, responded: “Great! Someone will attend to you shortly.” The problem was that there was no one to attend to him, since the agent did not have the ability to coordinate visits or inform a human about the arrival of a customer. In fact, all visits had to be scheduled in advance, and only during weekends in a specific time range. And in the prompt given to the agent, these instructions were clearly indicated. But the agent, after having an extensive conversation with the user, simply ignored these instructions and took him on a journey that only resulted in a waste of time… and a potential sale.
This story is real and I tell it as an anecdote. But now imagine another agent. One that attends an ice cream shop, specializing in flavor combinations with creatively named ice creams. A user asks the agent about the most popular ice cream, and the agent responds that it is the “Pandora’s Box.” But the user is allergic to peanuts, and the “Pandora’s Box” is an ice cream that contains peanuts. The user specifically asks if the ice cream contains peanuts, and the agent responds that it does not, since the language model does not have access to detailed information about the ingredients of each ice cream; only their name, price, and availability. The user, trusting and happy, decides to confirm and order the “Pandora’s Box” for delivery. The rest of the story you can imagine.
Okay, perhaps this imaginary story is very extreme, but it is something that could happen. After all, even large platforms like Amazon have experienced outages this month due to issues in their AI systems. Okay, maybe your business doesn’t have AI systems so deeply ingrained that an error could paralyze your entire operation. After all, you only need an intelligent agent to attend to your customers via chat. What’s that? You connected your agent to your e-commerce, and a customer convinced it to generate a coupon with a 90% discount because they said it was their birthday? The point is that, to evaluate if AI is a good solution for your business, it is essential to visualize the risks associated with its use and the impact they can have when it fails or hallucinates. In fact, many times it is more useful to think about the project from the perspective of “How bad would it be if AI fails?” rather than “How good would it be if AI works well?”.
If the impact of a mistake is high enough to damage your business, then it’s necessary to be realistic and invest the effort required to mitigate those risks.
Because at the end of the day, everyone makes mistakes. And if it happens to tech giants, it could also happen to your small agent that you innocently connected to your WhatsApp, your e-commerce, your CRM, your inventory system, and your email.
Don’t forget to make frequent backups!